Large language models (LLMs) were shown to encode word form variations, such as
"walk"→"walked", as linear directions in embedding space. However, standard tokenization
algorithms treat these variations as distinct tokens—filling the size-capped vocabulary with
surface form variants (e.g., "walk", "walking", "Walk"), at the expense of less frequent words
and multilingual coverage.
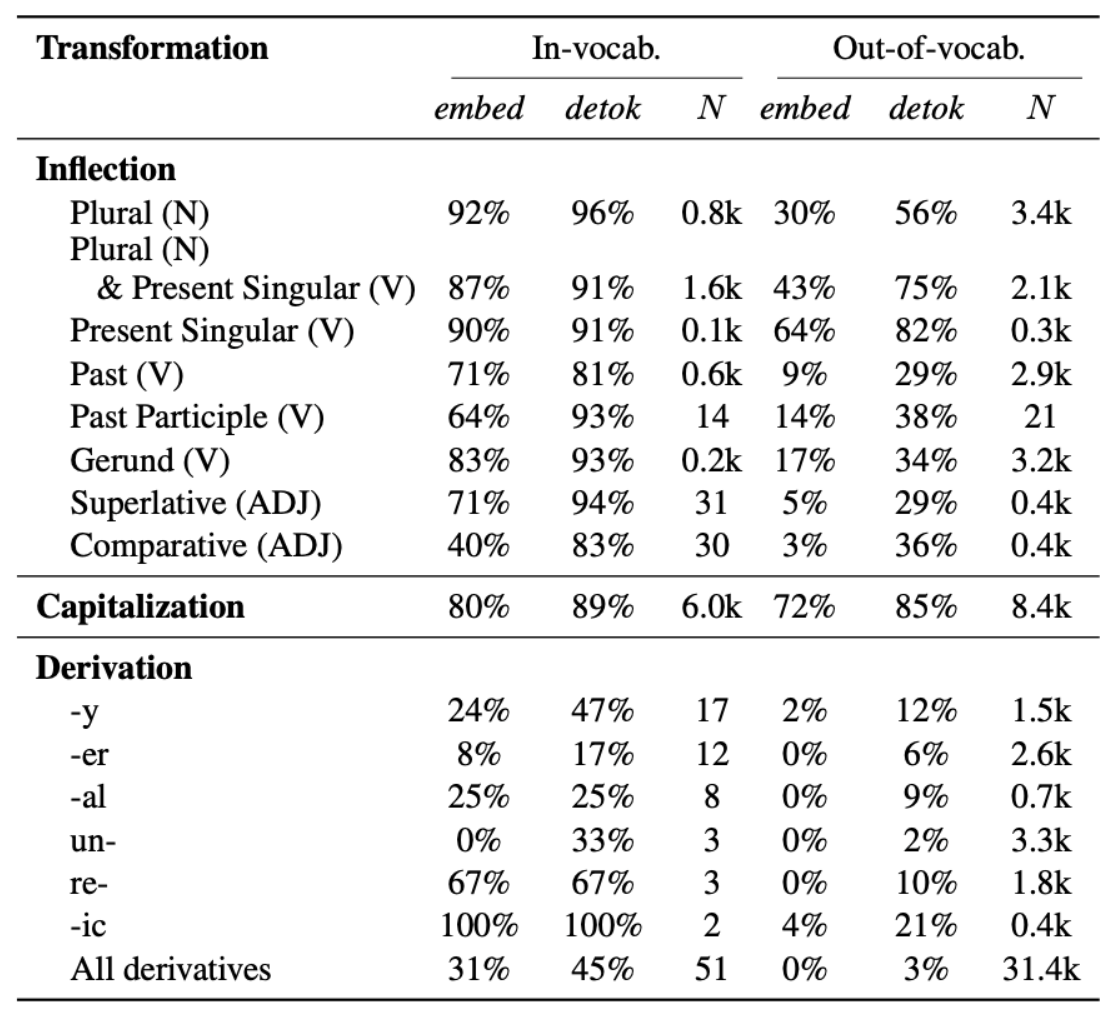
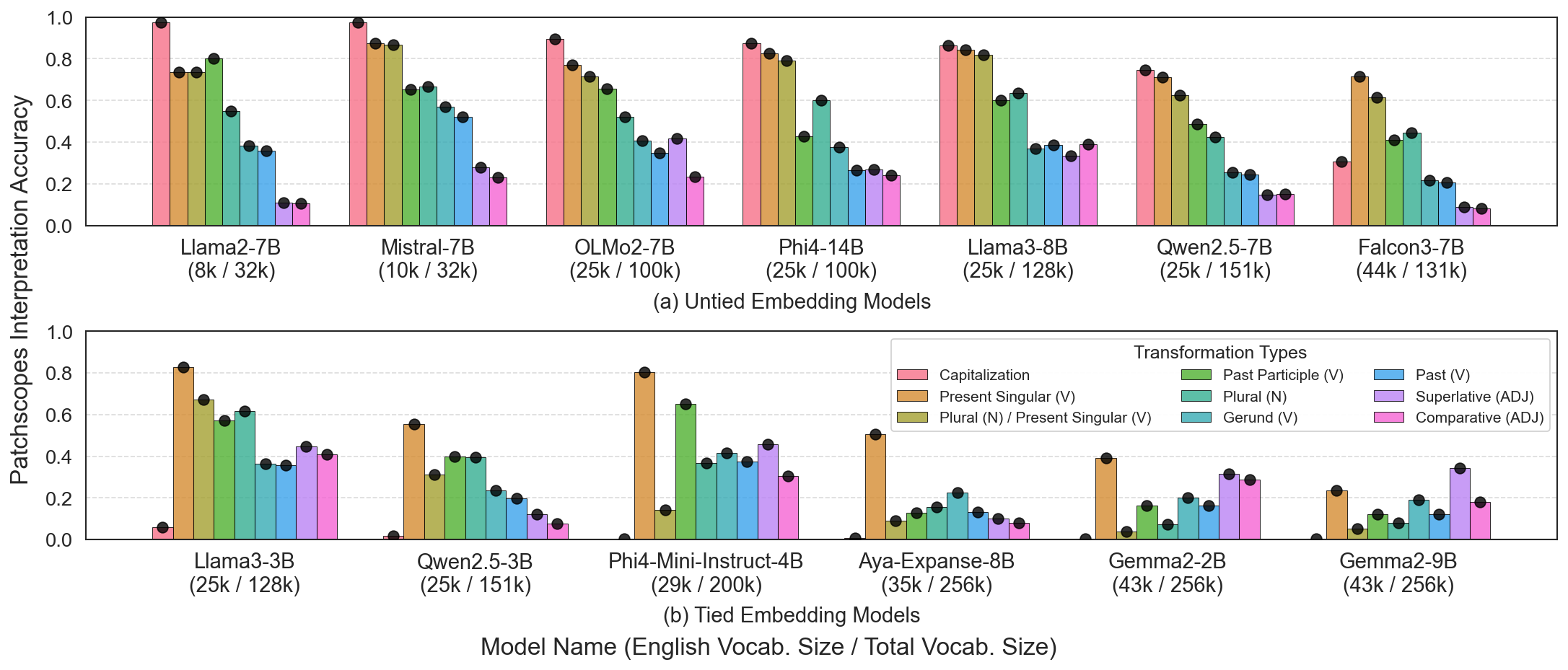
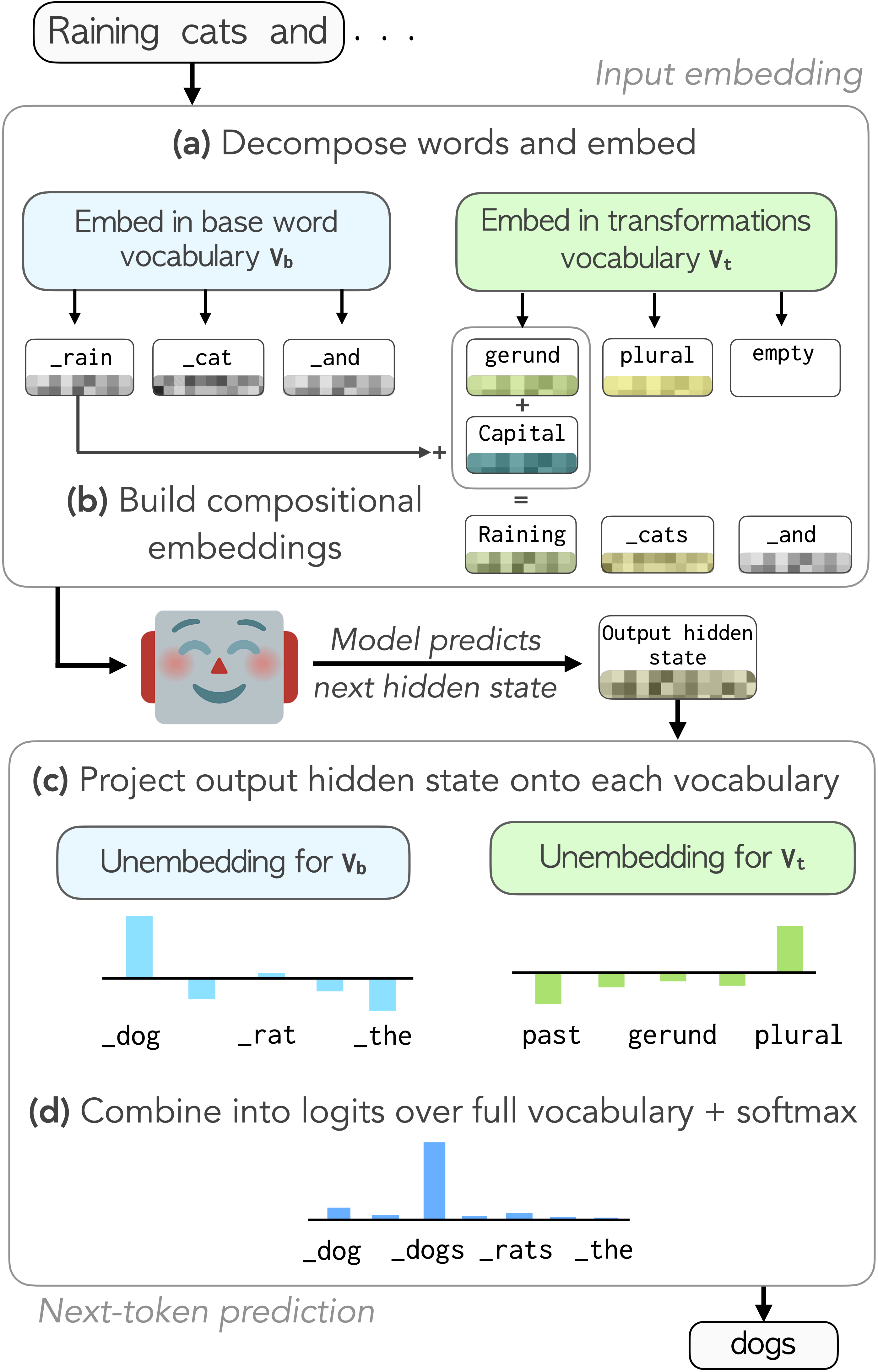
We show that many of these variations can be captured by transformation vectors—additive
offsets that yield the appropriate word's representation when applied to the base form word
embedding—in both the input and output spaces. Building on this, we propose a compact reshaping
of the vocabulary: rather than assigning unique tokens to each surface form, we compose them from
shared base form and transformation vectors (e.g., "walked" = "walk" + past tense).
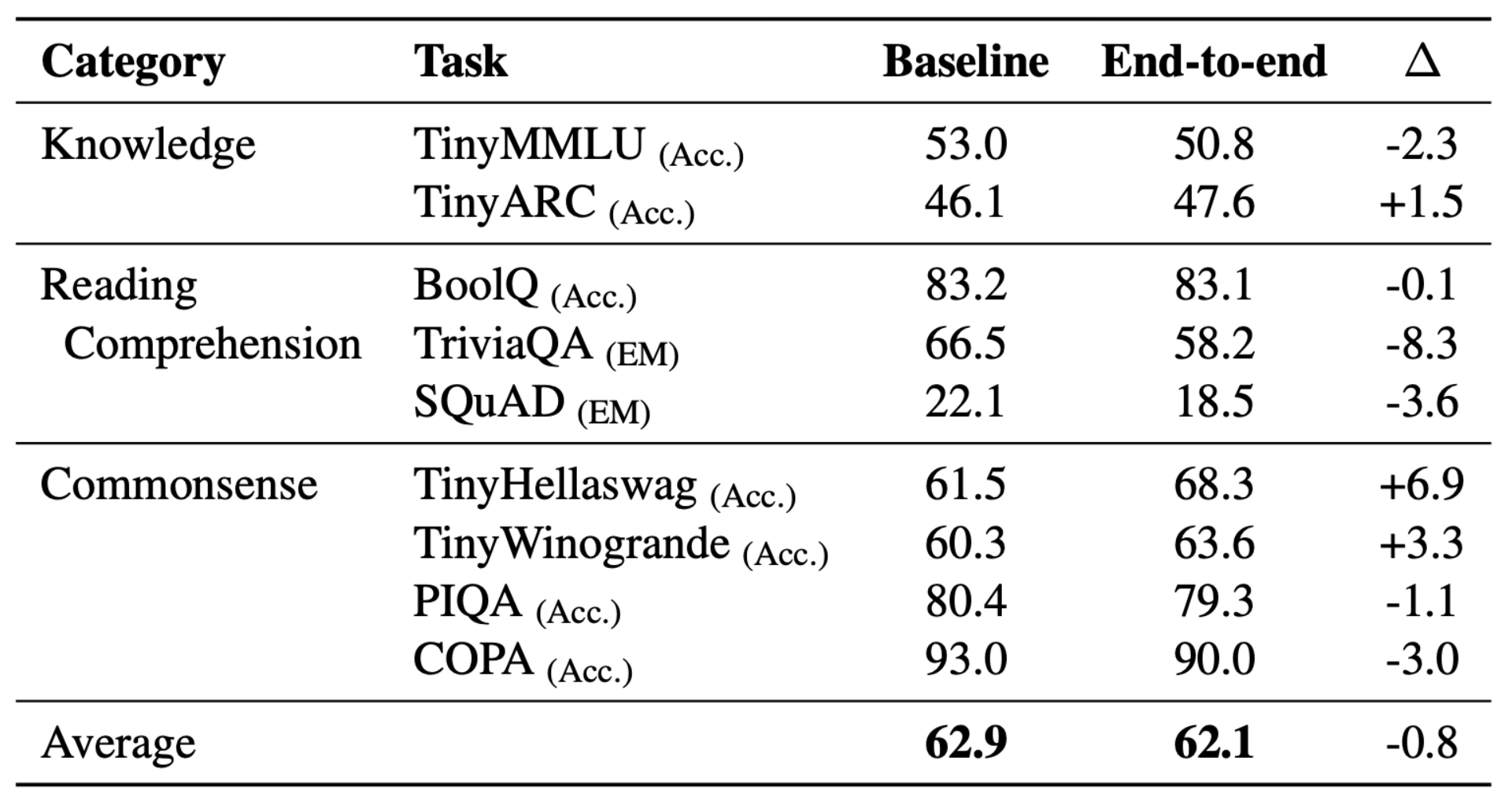
We apply our approach to multiple LLMs and across five languages, removing up to 10% of vocabulary
entries—thereby freeing space to allocate new, more diverse tokens. Importantly, we do so while
also expanding vocabulary coverage to out-of-vocabulary words, with minimal impact on downstream
performance, and without modifying model weights.